
RE/flex
The regex-centric, fast lexical analyzer generator for C++
RE/flex is a more powerful free open source alternative to the Flex fast lexical analyzer generator. RE/flex accepts more expressive lexer specifications with Unicode patterns, indent/nodent/dedent anchors, lazy quantifiers, word boundaries and many other modern features compared to Flex. RE/flex generates clean source code lexer classes that are thread-safe. RE/flex accepts Flex specifications and is compatible with Bison (Yacc). RE/flex also offers an extremely fast regex library for C++.
How does RE/flex work?
The RE/flex lexical analyzer generator takes a lexer specification and generates a C++ lexer class saved to lex.yy.h and lex.yy.cpp. The lexer class is saved in clean source code that is easy to understand. This class is then compiled and linked with the RE/flex library to produce a scanner:
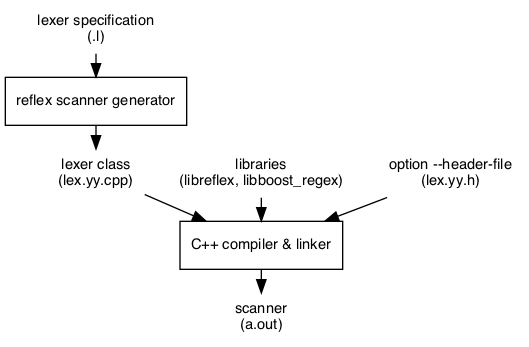
The generated scanner may be a stand-alone application or be part of a larger program, such as a compiler that tokenizes the input:
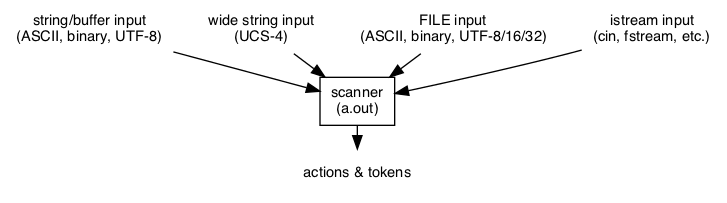
A smart input class is used by the scanner to process diverse input sources, including UTF-8/16/32 files, streams, strings, and memory. The generated scanner executes actions, typically to produce tokens for a parser. The actions are triggered by matching patterns to the input as specified in the lexer specification.
What is different?
RE/flex differs in many respects from other lexical analyzer generators, supporting full Unicode, indent/nodent/dedent anchors, lazy quantifiers, word boundaries, and more. Perhaps the most striking difference is that there are two regex matching engines to choose from for the generated scanner: the RE/flex matcher or the Boost.Regex library. The RE/flex matcher runs in direct code as a super fast deterministic finite state machine or as a deterministic finite state machine table, depending on options selected. The Boost.Regex library offers a richer regex syntax but uses a slower non-deterministic finite state machine to match input.
See also